数据库之SQL(构架、索引和视图) |
您所在的位置:网站首页 › sql 图形化 › 数据库之SQL(构架、索引和视图) |
数据库之SQL(构架、索引和视图)
|
一、创建视图 两种方式: 1、图形化界面直接添加 2、SQL语句添加 图形化界面添加 执行结果:
执行结果:
 SQL语句添加:
SQL语句添加:
 为什么要使用视图?
为了查看不同表格中的关联数据,可直接从视图中查询,无需再创建一个SELECT 语句,方便我们的查询。
为什么要使用视图?
为了查看不同表格中的关联数据,可直接从视图中查询,无需再创建一个SELECT 语句,方便我们的查询。
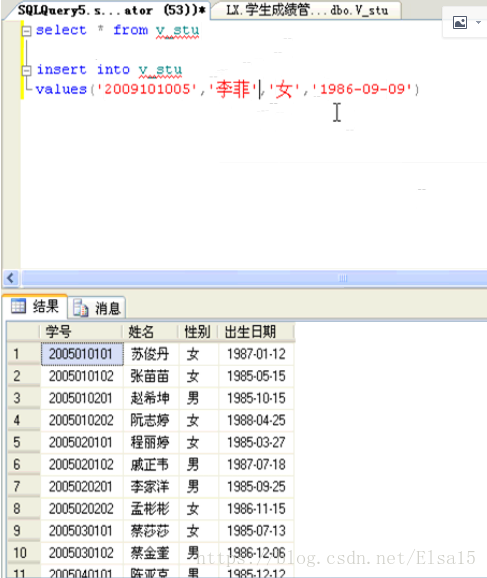
二、修改和删除视图 两种方法: 1、图形化界面 直接点击设计继续界面画的修改,删除则是单击右键删除2、SQL语句 修改视图: 运行效果: 删除视图: drop view “视图名称” 三、通过视图修改数据 无法修改的状况,即修改前注意事项: 如何通过SQL语句在视图中插入数据? 首先利用SQL语句查询视图内容,然后再用insert语句插入数据即可,如图: 四、索引概述 为什么会有索引? 这个问句等同于:为什么书本前要有目录。 提高检索速度,降低页面相应时间,加快表与表的索引速度。 五、创建索引 如何创建索引 1、图形界面操作索引的创建 如果设定了主键,那么就无法创建聚集索引,除非把主键删除,所以我们要创建非聚集索引
2、SQL语句创建
如果设定了主键,那么就无法创建聚集索引,除非把主键删除,所以我们要创建非聚集索引
2、SQL语句创建
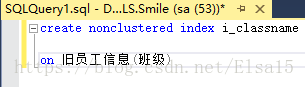 代码中nonclustered是代表什么意思呢?
非聚集索引
六、管理索引
1、管理索引,管理的是什么?
查看索引,删除索引
2、索引数量的影响?
对于经常插入更新的表,应减少索引量,频繁数据变更,反而会降低搜索效率。
3、删除索引的方法?
①图形操作,右击删除
②SQL(需要指定表名,否则会把其他表中相同的索引也给删掉)
代码中nonclustered是代表什么意思呢?
非聚集索引
六、管理索引
1、管理索引,管理的是什么?
查看索引,删除索引
2、索引数量的影响?
对于经常插入更新的表,应减少索引量,频繁数据变更,反而会降低搜索效率。
3、删除索引的方法?
①图形操作,右击删除
②SQL(需要指定表名,否则会把其他表中相同的索引也给删掉)
 七、全文索引和目录(使用最频繁)
如何创建全文索引?
七、全文索引和目录(使用最频繁)
如何创建全文索引?

九、修改和删除架构 修改架构: 图形化界面操作---选择要修改的表名称,单击右键,选择设计,在视图中调出属性窗口,找到架构直接选择更改即可。 数据表架构修改: 选择架构,右击属性,进行修改。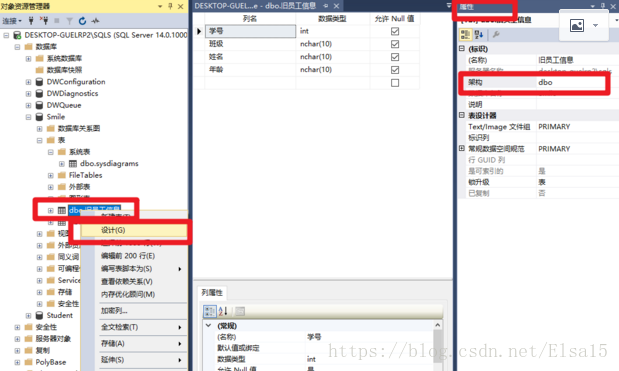 删除架构
图形化界面删除 :单击删除即可,但架构中有对象的话是无法删除的
SQL语句删除:drop语句
十、聚集索引和非聚集索引
删除架构
图形化界面删除 :单击删除即可,但架构中有对象的话是无法删除的
SQL语句删除:drop语句
十、聚集索引和非聚集索引
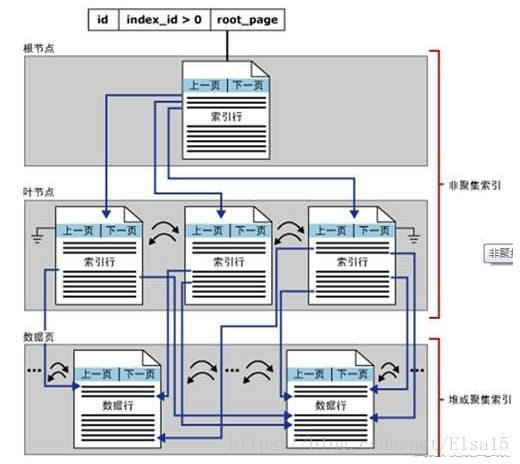
通俗的举例: 其实,我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。 如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。附上图表就会更清晰了: 十一:架构、索引和视图的思维导图 |






【本文地址】
今日新闻 |
推荐新闻 |